MySQL高可用
1.复制
MySQL支持两种复制方式
- 基于行的复制: 将实际数据记录在二进制日志中
- 基于语句的复制: 主库会记录那些造成数据更改的查询,当备库读取并重放事件时,实际上只是把主库上执行过的SQL再执行一遍 这两种方式都是通过在主库中记录二进制日志,在备库重放日志的方式来实现异步的数据复制.这意味着,在通过一时间点备库上的数据可能与主库存在不一致,并且无法保证主备之间的延迟.
复制比较常见的用途
- 数据分布
- 负载均衡
- 备份
- 高可用性和故障切换
- MySQL升级测试
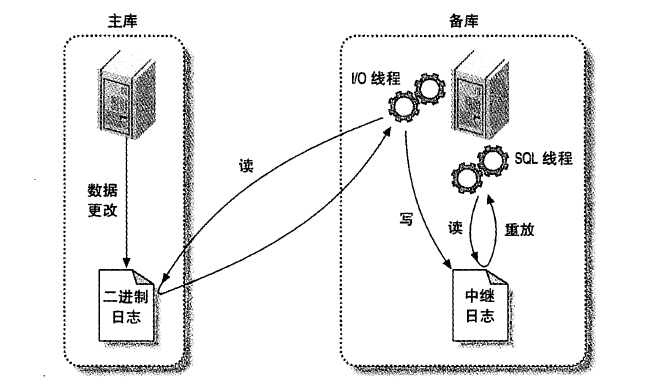
复制
- 在主库上把数据更改记录到二进制日志(Binary Log)中
- 备库将主库上的日志复制到自己的中继日志(Reday Log)中
- 备库读取中继日志中的事件,将其重放到备库数据之上
复制的基本原则
- 一个MySQL备库实例只能有一个主库
- 每个备库必须有一个唯一的服务器ID
- 一个主库可以有多个备库(或者相应的,一个备库可以有多个兄弟备库)
- 如果打开了
log_slave_updates选项,一个备库可以把其主库上的数据变化传播到其他备库
2.可扩展
可扩展性是当增加资源以处理负载和增加容量时系统能够获得的投资产出率(ROI).
向上扩展 向上扩展(也称垂直扩展)意味着购买更多性能强悍的硬件.
向外扩展
- 按功能拆分. 意味着不同的节点执行不同的任务
- 数据分片. 将数据分割成一块,然后存储到不同的节点中
- 选择分区键. 一个好的分区键通常是数据库中一个非常重要实体的主键
- 多个分区键
- 跨分片查询
- 分片数据、分片和节点
- 节点手上部署分片
- 固定分配. 比如常见的哈希函数和取模运算
- 动态分配. 使用分区表, 比较灵活,可以对数据存储位置做细粒度的控制.
- 混合动态分配和固定分配
- 显示分配
- 重新均衡分配数据
- 生成全局唯一的ID. auto_increment_increment/全局节点中创建表/使用memcached incr()函数/ 赔了分配数据 / 使用复合键 / 使用GUID值
负载均衡
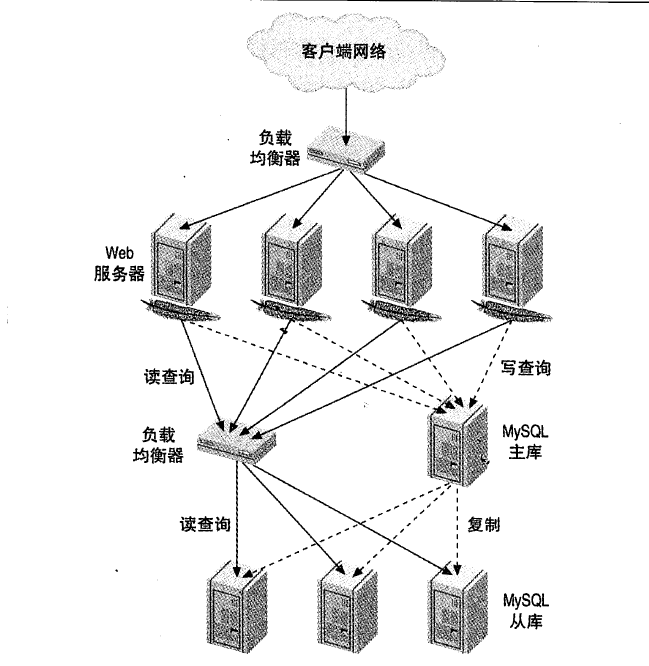 负载均衡算法
负载均衡算法
- 随机: 从可用的服务器池中选择一个服务器来处理请求
- 轮询: 以循环顺序发送请求到服务器
- 最少连接数: 下一个连接请求分配给拥有最少活跃链接的服务器
- 最快响应: 能够最快处理请求的服务器接受下一个连接
- 哈希: 通过连接的源IP地址进行哈希,将其映射到池中的同一个服务器上
- 权重: 负载均衡器能够结合使用上述几种算法
3.高可用性
导致宕机的原因
- 运行环境的问题中, 最普遍的是磁盘空间耗尽
- 性能问题中, 最普遍的是运行很糟糕的SQL
- 糟糕的Schema和索引涉及是第二大影响性能的问题
- 复制问题通常由于主备数据不一致导致
- 数据丢失问题通常是由于 DROP TABLE的误操作,并总是伴随着缺少可用备份的问题