# Disruptor
无锁的缓存框架: http://lmax-exchange.github.io/disruptor/
1.生产者-消费者模式
1.1 介绍
生产者-消费者模式是一个经典的多线程设计模式, 它为线程间的协作提供了良好的解决方案.
- 生产者线程: 负责提交用户请求
- 消费者线程: 负责处理具体生产者提交的任务
- 生产者和消费者之间通过共享内存缓存区进行通信
注意:生产者-消费者模式中的内存缓存区的主要功能是数据在多线程间的共享,此外,t通过该缓冲区, 可以缓解生产者和消费者间的性能差.
1.2 生产者-消费者模式主要角色
| 角色 | 作用 |
|---|---|
| 生产者 | 用户提交用户请求, 提取用户任务, 并装入内存缓冲区 |
| 消费者 | 在内存缓冲区中提取并处理任务 |
| 内存缓存区 | 缓存生产者提交的任务或数据, 供消费者使用 |
| 任务 | 生产者向内存缓冲区提交的数据结构 |
| Main | 使用生产者和消费者的客户端 |
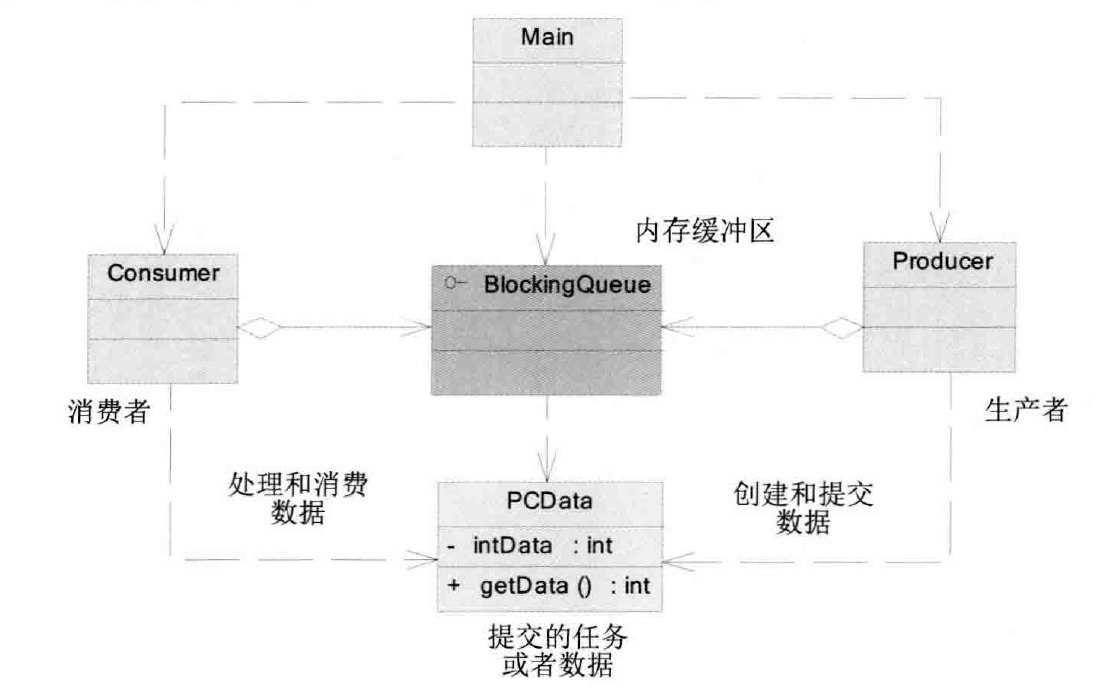
NOTE: BlockingQueue用于消费者和生产者是一个不错的选择.它可以很自然地实现作为生产者和消费者的内存缓冲区.但是BlockingQueue并不是一个高性能的实现,它完全使用锁和阻塞等待来实现线程间的同步.在高并发场合,它的性能并不是特别的优越.相反, ConcurrentLinkQueue(秘诀在于大量使用了无锁的CAS操作)是一个高性能的队列, BlockingQueue只是为了方便数据共享.
2. disruptor
2.1 简介
disruptor
- LMAX的高性能低延迟异步处理框架
- 基于无锁循环队列,采用数组实现
- 能够在无锁的情况下实现并发操作
- 号称单线程里每秒处理 6百万订单
2.2 disruptor的数据结构
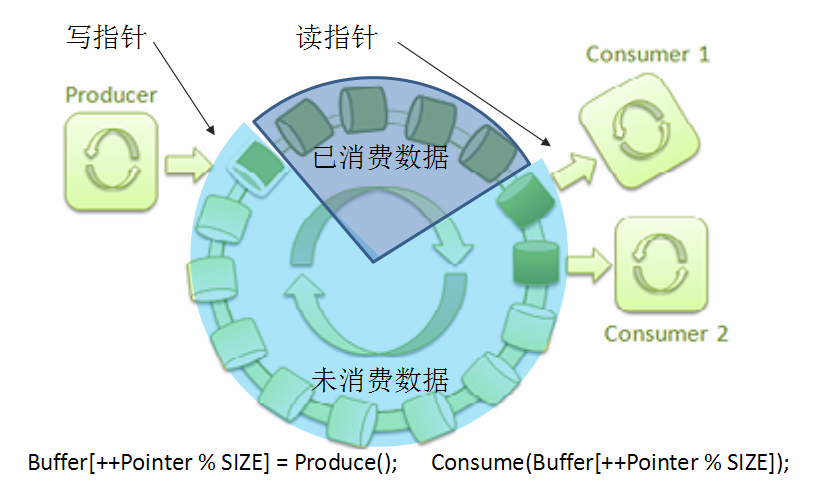
2.3 Disruptor核心组件
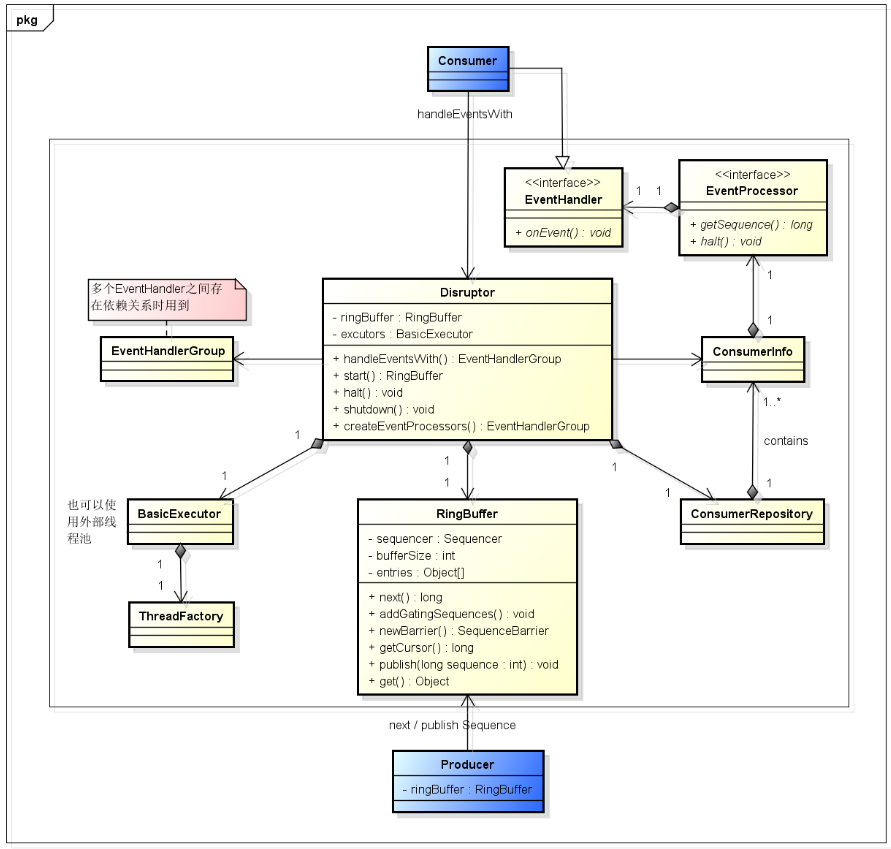
Disruptor: 协调类,入口类,生成生产者、消费者以及他们之间的协调关系RingBuffer: 负责对数据(事件)进行存储和更新,大小必须为2的n次方Sequence: 用于跟踪标识某个特定的事件处理者的处理进度Sequencer: Disruptor 的真正核心。有两个实现类 SingleProducerSequencer、MultiProducerSequencerSequence Barrier: 序号栅栏,管理和协调生产者的游标序号和各个消费者的序号Event: 通过 Disruptor 进行交换的数据类型EventFactory: 生成Event的工厂,通过该工厂方法填充RingBufferEventProcessor: 一个Runnable, 其run方法是消费者的消费过程EventHandler: 用于处理事件,是 Consumer 的真正实现Wait Strategy: 定义 Consumer 如何进行等待下一个事件的策略
2.4 disruptor高效的原因
1.无锁
| 队列 | 有界性 | 锁 | 数据结构 |
|---|---|---|---|
ArrayBlockingQueue |
bounded` | 加锁 | arraylist |
LinkedBlockingQueue |
optionally-bounded` | 加锁 | linkedlist |
ConcurrentLinkedQueue |
unbounded` | 无锁 | linkedlist |
LinkedTransferQueue |
unbounded` | 无锁 | linkedlist |
PriorityBlockingQueue |
unbounded` | 加锁 | heap |
DelayQueue |
unbounded` | 加锁 | heap |
- 单线程情况下,不加锁的性能 > CAS操作的性能 > 加锁的性能.
- 在多线程情况下,CAS的性能是锁的8倍.
disruptor实现
每个生产者或者消费者线程,会先申请可以操作的元素在数组中的位置,申请到之后,直接在该位置写入或者读取数据
- 单线程: 没有锁也没有CAS
- 多线程: 多线程写存在CAS
相对于传统方式的优点
- 没有竞争=没有锁=非常快
- 所有访问者都记录自己的序号,允许多个生产者与多个消费者共享相同的数据结构
2.缓存行填充
伪共享
当写指针、读指针存储在同一CPU缓存行时,一个CPU核心对写指针的修改会使另一个核心的该缓存行失效,导致使用读指针被延迟.
缓存行特点
- 缓存是由缓存行组成的,通常是64字节
- 一个缓存行中可以存8个long类型的变量
- 如加载一个long值,会额外加载附近7个值到缓存行
- 加载的值有一个修改,缓存行整体失效
disruptor实现
缓存行填充: 使用多个long变量填充,从而确保一个序号独占一个缓存行
class LhsPadding
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding
{
protected volatile long value;
}
class RhsPadding extends Value
{
protected long p9, p10, p11, p12, p13, p14, p15;
}
内部数组的构造: 实际产生的数组大小是缓冲区实际大小再加上两倍的BUFFER_PAD.这就相当于在这个数据的头部和尾部两端各增加了BUFFER_PAD个填充,使得整个数组被载入Cache时不会受到其它变量的影响而失效.
this.entries = new Object[sequencer.getBufferSize() + 2 * BUFFER_PAD];
3.内存屏障
内存屏障: volatile
原理: 如果字段是volatile,Java内存模型将在写操作后插入一个写屏障指令,在读操作前插入一个读屏障指令
4.避免频繁GC
5.批量生产消费
Disruptor实现
- 消费者一次消费尽量多的产品
- 生产者多次生产一次发布
2.5 Disruptor消费的选择策略
2.5.1 BlockingWaitStrategy
默认的策略.使用BlockingWaitStrategy和使用BlockingQueue是非常类似的,它们都是用锁和条件(Condition)进行数据的监控和线程的唤醒.因为涉及到线程的切换,BlockingWaitStrategy策略是最节省CPU, 但是在高并发性能表现最糟糕的一种等待策略.
public final class BlockingWaitStrategy implements WaitStrategy{
private final Lock lock = new ReentrantLock();
private final Condition processorNotifyCondition = lock.newCondition();
@Override
public long waitFor(long sequence, Sequence cursorSequence, Sequence dependentSequence, SequenceBarrier barrier)
throws AlertException, InterruptedException{
long availableSequence;
if (cursorSequence.get() < sequence){
lock.lock();
try{
while (cursorSequence.get() < sequence){
barrier.checkAlert();
processorNotifyCondition.await();
}
}finally{
lock.unlock();
}
}
while ((availableSequence = dependentSequence.get()) < sequence){
barrier.checkAlert();
ThreadHints.onSpinWait();
}
return availableSequence;
}
@Override
public void signalAllWhenBlocking(){
lock.lock();
try{
processorNotifyCondition.signalAll();
}finally{
lock.unlock();
}
}
}
2.5.2 SleepingWaitStrategy
这个策略也是对CPU使用率非常保守的.它会在循环中不断等待数据.它会先进行自旋等待.如果不成功, 则使用Thread.yield()让出CPU,并最终使用LockSupport.parkNanos()进行线程休眠,已确保不占用太多的CPU数据.因此,这个策略对于数据处理可能产生比较高的平均延迟.它比较适合于对延迟要求不是特别高的场合,好处是它对生产者线程的影响最小.典型的应用场景是异步日志.
public final class SleepingWaitStrategy implements WaitStrategy{
private static final int DEFAULT_RETRIES = 200;
private static final long DEFAULT_SLEEP = 100;
private final int retries;
private final long sleepTimeNs;
public SleepingWaitStrategy(){ this(DEFAULT_RETRIES, DEFAULT_SLEEP);}
public SleepingWaitStrategy(int retries){this(retries, DEFAULT_SLEEP);}
public SleepingWaitStrategy(int retries, long sleepTimeNs){this.retries = retries;this.sleepTimeNs = sleepTimeNs;}
@Override
public long waitFor(
final long sequence, Sequence cursor, final Sequence dependentSequence, final SequenceBarrier barrier)
throws AlertException{
long availableSequence;
int counter = retries;
while ((availableSequence = dependentSequence.get()) < sequence){
counter = applyWaitMethod(barrier, counter);
}
return availableSequence;
}
@Override
public void signalAllWhenBlocking() {
}
private int applyWaitMethod(final SequenceBarrier barrier, int counter)
throws AlertException{
barrier.checkAlert();
if (counter > 100){
--counter;
}else if (counter > 0){
--counter;
Thread.yield();
}else{
LockSupport.parkNanos(sleepTimeNs);
}
return counter;
}
}
2.5.3 YieldingWaitStrategy
这个策略用于低延迟的场合.消费者会不断循环监控缓冲区变化.在循环内部,它会使用Thread.yield()让出CPU给别的线程执行时间.如果需要一个高性能的系统,并且对延迟有较为严格的要求,则可以考虑这种策略.使用这个策略时,相当于消费者线程变声成为了一个内部执行了Thread.yield()的死循环.因此,最好有多于消费者线程数量的逻辑CPU数量(这里的逻辑CPU,指的是"双核四线程"中的四线程),否则,整个应用程序恐怕都会受到影响.
public final class YieldingWaitStrategy implements WaitStrategy {
private static final int SPIN_TRIES = 100;
@Override
public long waitFor(
final long sequence, Sequence cursor, final Sequence dependentSequence, final SequenceBarrier barrier)
throws AlertException, InterruptedException {
long availableSequence;
int counter = SPIN_TRIES;
while ((availableSequence = dependentSequence.get()) < sequence) {
counter = applyWaitMethod(barrier, counter);
}
return availableSequence;
}
@Override
public void signalAllWhenBlocking() {
}
private int applyWaitMethod(final SequenceBarrier barrier, int counter)
throws AlertException {
barrier.checkAlert();
if (0 == counter) {
Thread.yield();
} else {
--counter;
}
return counter;
}
}
2.5.4 BusySpinWaitStrategy
这个是最疯狂的等待策略了,它就是一个死循环!消费者线程会尽最大努力疯狂监控缓冲区的变化.因此,它会吃掉所有的CPU资源.只有在对延迟非常苛刻的场合可以考虑使用它(或者说,你的系统真的非常繁忙).因为在这里你等同开启了一个死循环监控,所有,你的物理CPU数量必需要大于消费者线程数.
public final class BusySpinWaitStrategy implements WaitStrategy {
@Override
public long waitFor(
final long sequence, Sequence cursor, final Sequence dependentSequence, final SequenceBarrier barrier)
throws AlertException, InterruptedException {
long availableSequence;
while ((availableSequence = dependentSequence.get()) < sequence) {
barrier.checkAlert();
ThreadHints.onSpinWait();
}
return availableSequence;
}
@Override
public void signalAllWhenBlocking() {
}
}