ElasticSearch Function_score
1. 控制相关度 function_score
- 在使用ES进行全文搜索时,搜索结果默认会以文档的相关度进行排序,而这个 "文档的相关度",是可以透过function_score 自己定义的,也就是说我们可以透过使用function_score,来控制 "怎么样的文档相关度更高" 这件事
function_score是专门用于处理文档_score的DSL,它允许为每个主查询query匹配的文档应用加强函数,以达到改变原始查询评分 score的目的function_score会在主查询query结束后对每一个匹配的文档进行一系列的重打分操作,能够对多个字段一起进行综合评估,且能够使用 filter 将结果划分为多个子集 (每个特性一个filter),并为每个子集使用不同的加强函数
1.1 function_score 提供了几种加强_score计算的函数
weight: 设置一个简单而不被规范化的权重提升值- weight加强函数和 boost参数类似,可以用于任何查询,不过有一点差别是weight不会被Lucenenomalize成难以理解的浮点数,而是直接被应用 (boost会被nomalize)
- 例如当 weight 为2时,最终结果为
new_score = old_score * 2
field_value_factor: 将某个字段的值乘上old_score- 像是将字段shareCount 或是字段likiCount 作为考虑因素,
new_score = old_score * 那个文档的likeCount的值
- 像是将字段shareCount 或是字段likiCount 作为考虑因素,
random_score: 为每个用户都使用一个不同的随机评分对结果排序,但对某一具体用户来说,看到的顺序始终是一致的衰减函数 (linear、exp、guass): 以某个字段的值为基准,距离某个值越近得分越高script_score: 当需求超出以上范围时,可以用自定义脚本完全控制评分计算,不过因为还要额外维护脚本不好维护,因此尽量使用ES提供的评分函数,需求真的无法满足再使用script_score
1.2 function_scroe其他辅助的参数
boost_mode: 决定 old_score 和加强score 如何合并multiply(默认):new_score = old_score * 加强scoresum:new_score = old_score + 加强scoremin: old_score 和加强score 取较小值,new_score = min(old_score, 加强score)max: old_score 和加强score 取较大值,new_score = max(old_score, 加强score)replace: 加强score直接替换掉old_score,new_score = 加强score
score_mode: 决定functions里面的加强score们怎么合并,会先合并加强score们成一个总加强score,再使用总加强score去和old_score做合并,换言之就是会先执行score_mode,再执行boost_modemultiply (默认)sumavgfirst: 使用首个函数(可以有filter,也可以没有)的结果作为最终结果maxmin
max_boost: 限制加强函数的最大效果,就是限制加强score最大能多少,但要注意不会限制old_score- 如果加强score超过了max_boost限制的值,会把加强score的值设成max_boost的值
- 假设加强score是5,而max_boost是2,因为加强score超出了max_boost的限制,所以max_boost就会把加强score改为2
- 简单的说,就是加强
score = max(加强score, max_boost)
1.3 function_score查询模板
- 如果要使用function_score改变分数,要使用function_score查询
简单的说,就是在一个function_score内部的query的全文搜索得到的
_score基础上,给他加上其他字段的评分标准,就能够得到把 "全文搜索 + 其他字段" 综合起来评分的效果 - 单个加强函数的查询模板GET 127.0.0.1/mytest/doc/_search { "query": { "function_score": { "query": {.....}, //主查询,查询完后这里自己会有一个评分,就是old_score "field_value_factor": {...}, //在old_score的基础上,给他加强其他字段的评分,这里会产生一个加强score,如果只有一个加强function时,直接将加强函数名写在query下面就可以了 "boost_mode": "multiply", //指定用哪种方式结合old_score和加强score成为new_score "max_boost": 1.5 //限制加强score的最高分,但是不会限制old_score } } }多个加强函数的查询模板
- 如果有多个加强函数,那就要使用functions来包含这些加强函数们,functions是一个数组,里面放着的是将要被使用的加强函数列表
- 可以为functions里的加强函数指定一个filter,这样做的话,只有在文档满足此filter的要求,此filter的加强函数才会应用到文挡上,也可以不指定filter,这样的话此加强函数就会应用到全部的文挡上
- 一个文档可以一次满足多条加强函数和多个filter,如果一次满足多个,那么就会产生多个加强score,因此ES会使用score_mode定义的方式来合并这些加强score们,得到一个总加强score,得到总加强score之后,才会再使用boost_mode定义的方式去和old_score做合并
- 像是下面的例子,field_value_factor和gauss这两个加强函数会应用到所有文档上,而weight只会应用到满足filter的文档上,假设有个文档满足了filter的条件,那他就会得到3个加强score,这3个加强score会使用sum的方式合并成一个总加强score,然后才和old_score使用multiply的方式合并
GET 127.0.0.1/mytest/doc/_search { "query": { "function_score": { "query": {.....}, "functions": [ //可以有多个加强函数(或是filter+加强函数),每一个加强函数会产生一个加强score,因此functions会有多个加强score { "field_value_factor": ... }, { "gauss": ... }, { "filter": {...}, "weight": ... } ], "score_mode": "sum", // 决定加强score们怎么合并成一个总加强score "boost_mode": "multiply" // 决定总加强score怎么和old_score合并 } } }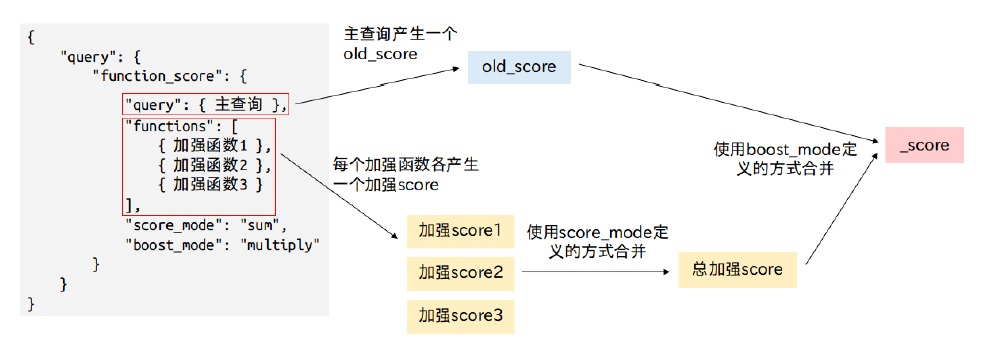
1.4 不要执著在调整function_score上
- 文档相关度的调整非常玄,"最相关的文档" 是一个难以触及的模糊概念,每个人对文档排序有着不同的想法,这很容易使人陷入持续反覆调整,但是确没有明显的进展
- 为了避免跳入这种死循环,在调整function_score时,一定要搭配监控用户操作,才有意义
- 像是如果返回的文档是用户想要的高相关的文档,那么用户就会选择前10个中的一个文档,得到想要的结果,反之,用户可能会来回点击,或是尝试新的搜索条件
- 一旦有了这些监控手段,想要调适完美的function_score就不是问题
- 因此调整function_score的重点在于,要透过监控用户、和用户互动,慢慢去调整我们的搜索条件,而不要妄想一步登天,第一次就把文档的相关度调整到最好,这几乎是不可能的,因为,连用户自己也不知道他自己想要什么
2. function_score - field_value_factor
- 有时候线性的计算
new_score = old_score * like值的效果并不是那么好,field_value_factor中还支持modifier、factor参数,可以改变like值对old_score的影响- modifier参数支持的值
none:new_score = old_score * like值- 默认状态就是none,线性
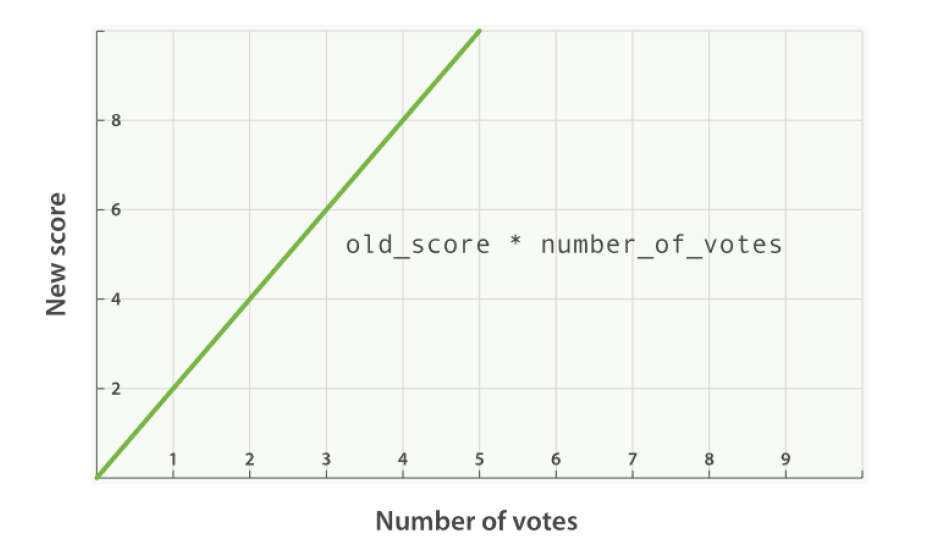
- 默认状态就是none,线性
log1p:new_score = old_score * log(1 + like值)- 最常用,可以让like值字段的评分曲线更平滑
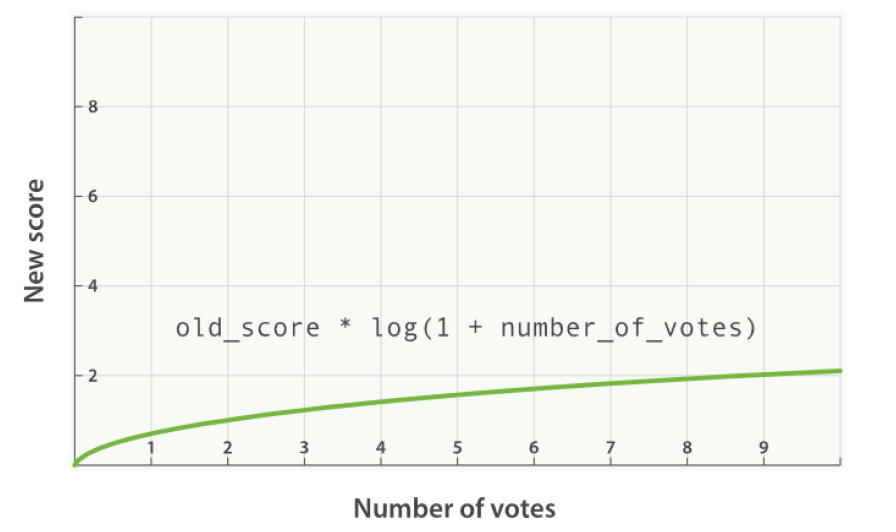
- 最常用,可以让like值字段的评分曲线更平滑
log2p:new_score = old_score * log(2 + like值)ln:new_score = old_score * ln(like值)ln1p:new_score = old_score * ln(1 + like值)ln2p:new_score = old_score * ln(2 + like值)square: 计算平方sqrt : 计算平方根reciprocal : 计算倒数
- factor参数
- factor作为一个调节用的参数,没有modifier那么强大会改变整个曲线,他仅改变一些常量值,设置factor>1会提升效果,factor<1会降低效果
- 假设modifier是log1p,那么加入了factor的公式就是
new_score = old_score * log(1 +factor * like值)
- modifier参数支持的值
就算加上了modifier,但是"全文评分与 field_value_factor函数值乘积" 的效果可能还是太大,我们可以通过参数boost_mode来决定old_score和加强score 合并的方法
- 如果将boost_mode改成sum,可以大幅弱化最终效果,特别是使用一个较小的factor时
- 加入了boost_mode=sum、且factor=0.1的公式变为
new_score = old_score + log(1 + 0.1 *like值)
另外使用field_value_factor时要注意,有的文档可能会缺少这个字段的值,因此这时就要加上missing来给这些缺失字段值的文档一个default的值
GET 127.0.0.1/mytest/doc/_search { "query": { "function_score": { "query": { "match": { "title": "ES" } }, "field_value_factor": { "field": "like", "modifier": "log1p", "factor": 0.1, "missing": 1 // 如果文档没有like值,就给他1的值让他去做log1p的运算 }, "boost_mode": "sum" } } }
3.function_score - weight
functions是一个数组,里面放着的是将要被使用的加强函数列表,我们在里面使用了3个filter去过滤数据,并且每个filter都设置了一个加强函数,并且还使用了一个会应用到所有文档的field_value_factor加强函数
- 可以为列表里的每个加强函数都指定一个filter,这样做的话,只有在文档满足此filter的要求,此filter的加强函数才会应用到文挡上,也可以不指定filter,这样的话此加强函数就会应用到全部的文挡上
- 一个文档可以一次满足多条加强函数和多个filter,如果一次满足多个,那么就会产生多个加强score
因此ES会先使用score_mode定义的方式来合并这些加强score们,得到一个总加强score,得到总加强score之后,才会再使用boost_mode定义的方式去和old_score做合并
GET 127.0.0.1/mytest/doc/_search { "query": { "function_score": { "query": { "match_all": {} // match_all查出来的所有文档的_score都是1 }, "functions": [ // 第一个filter(使用weight加强函数),如果language是java,加强score就是2 { "filter": { "term": { "language": "java" } }, "weight": 2 }, //第二个filter(使用weight加强函数),如果language是go,加强score就是3 { "filter": { "term": { "language": "go" } }, "weight": 3 }, // 第三个filter(使用weight加强函数),如果like数大于等于10,加强score就是5 { "filter": { "range": { "like": { "gte": 10 } } }, "weight": 5 }, // field_value_factor加强函数,会应用到所有文档上,加强score就是like值 { "field_value_factor": { "field": "like" } } ], "score_mode": "multiply", // 设置functions里面的加强score们怎么合并成一个总加强score "boost_mode": "multiply" // 设置old_score怎么和总加强score合并 } } }"hits": [ { "_score": 150, //go同时满足filter2、filter3,且还有一个加强函数field_value_factor产生的加强,因此加强score为3, 5, 10,总加强score为3*5*10=150 "_source": { "language": "go", "like": 10 } }, { "_score": 10, //java只满足filter1,但是因为还有field_value_facotr产生的加强score,因此加强score为2, 5,总加强score为2*5=10" _source": { "language": "java", "like": 5 } }, { "_score": 5, //python不满足任何filter,因此加强score只有field_value_factor的like值,就是5 "_source": { "language": "python", "like": 5 } } ]
- 其实weight加强函数也是可以不和filter搭配,自己单独使用的,只是这样做没啥意义,因为只是会给全部的文档都增加一个固定值而已
weight加强函数也可以用来调整每个语句的贡献度,权重weight的默认值是1.0,当设置了weight,这个weight值会先和自己那个{}里的每个句子的评分相乘,之后再通过score_mode和其他加强函数合并
- 下面的查询,公式为
new_score = old_score * [ (like值 * weight1) + weight2 ] 公式解析: weight1先加强like值(只能使用乘法),接着再透过score_mode定义的方法(sum)和另一个加强函数weight2合并,得到一个总加强score,最后再使用boost_mode定义的方法(默认是multiply)和old_score做合并,得到new_score
GET 127.0.0.1/mytest/doc/_search // Failure { "query": { "function_score": { "query": { "match_all": {} } }, "functions": [ { "field_value_factor": { "field": "like" }, "weight": 3 // weight1, 加强field_value_factor,只能使用乘法,无法改变 }, { "weight": 20 // weight2 } ], "score_mode": "sum" } } // SUCCESS { "query": { "function_score": { "query": { "match": { "title": "ES" } }, "functions": [ { "field_value_factor": { "field": "like" }, "weight": 3 // weight1, 加强field_value_factor,只能使用乘法,无法改变 }, { "weight": 20 // weight2 } ], "score_mode": "sum" } } }
- 下面的查询,公式为
4.function_score - random_score
在正常的查询下,有相同评分的 score 的文档会每次都会以相同次序出现,但是为了提高展现率,在此引入一些随机性可能会是个好主意,这能保证有相同评分的文档都能有均等相似的展现机率
- 但是,在随机的同时,除了想让不同的用户看到不同的随机次序之外,但也希望如果是同一用户翻页浏览时,结果的相对次序能始终保持一致,这种行为被称为一致随机(consistently random)
- 因此random_score加强函数除了能随机得到一个 0~1 的分数,也会使用一个seed值,来保障生成随机的顺序,当seed值相同时,生成的随机结果是一致的
使用random_score生成随机排序
- 注意在functions里,只有weight加强函数加了filter,也就是说只有like数小于等于5的文档,才会被weight加强函数加强
- 而random_score加强函数没有加filter,表示所有的文档都会被random_score随机排序一遍
GET 127.0.0.1/mytest/doc/_search { "query": { "function_score": { "query": { "match_all": {} }, "functions": [ { "filter": { "range": { "like": { "lte": 5 } } }, "weight": 2 }, { "random_score": { "seed": 100 } } ] } } }
5.function_score - 衰减函数 linear、exp、gauss
- 很多变量都可以影响用户对于酒店的选择,像是用户可能希望酒店离市中心近一点,但是如果价格足够便宜,也愿意为了省钱,妥协选择一个更远的住处
- 如果我们只是使用一个 filter 排除所有市中心方圆 100 米以外的酒店,再用一个filter排除每晚价格超过100元的酒店,这种作法太过强硬,可能有一间房在 500米,但是超级便宜一晚只要10元,用户可能会因此愿意妥协住这间房
- 为了解决这个问题,因此function_score查询提供了一组衰减函数(decay functions),让我们有能力在两个滑动标准(如地点和价格)之间权衡
- function_score支持的衰减函数有三种,分别是
linear、exp和gauss- linear、exp、gauss三种衰减函数的差别只在于衰减曲线的形状,在DSL的语法上的用法完全一样
linear: 线性函数是条直线,一旦直线与横轴0相交,所有其他值的评分都是0exp: 指数函数是先剧烈衰减然后变缓guass(最常用) : 高斯函数则是钟形的,他的衰减速率是先缓慢,然后变快,最后又放缓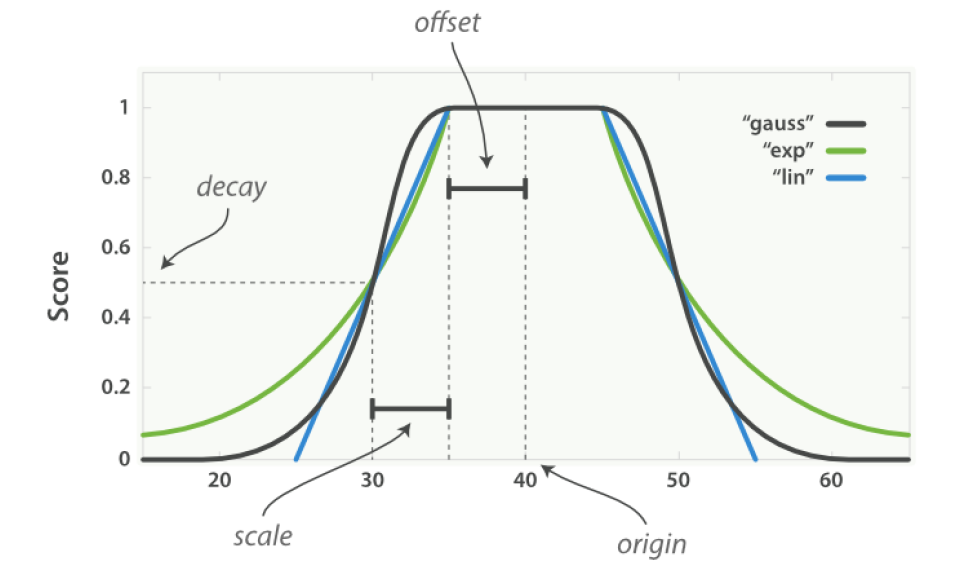
- 衰减函数们 (linear、exp、gauss) 支持的参数
origin: 中心点,或是字段可能的最佳值,落在原点(origin)上的文档评分_score为满分1.0,支持数值、时间以及 "经纬度地理座标点"(最常用) 的字段offset: 从origin 为中心,为他设置一个偏移量offset覆盖一个范围,在此范围内所有的评分_score也都是和origin一样满分1.0scale: 衰减率,即是一个文档从origin下落时,_score改变的速度decay: 从 origin 衰减到 scale 所得的评分_score,默认为0.5 (一般不需要改变,这个参数使用默认的就好了)- 以上面的图为例
- 所有曲线(linear、exp、gauss)的origin都是40,offset是5,因此范围在
40-5 <= value <=40+5的文档的评分_score都是满分1.0 - 而在此范围之外,评分会开始衰减,衰减率由scale值(此处是5)和decay值(此处是默认值0.5)决定,在
origin +/- (offset + scale)处的评分是decay值,也就是在30、50的评分处是0.5分 - 也就是说,在
origin + offset + scale或是origin - offset - scale的点上,得到的分数仅有decay分
- 所有曲线(linear、exp、gauss)的origin都是40,offset是5,因此范围在
- linear、exp、gauss三种衰减函数的差别只在于衰减曲线的形状,在DSL的语法上的用法完全一样
具体实例
- 假设有一个用户希望租一个离市中心近一点的酒店,且每晚不超过100元的酒店,而且与距离相比,我们的用户对价格更敏感,那麽使用衰减函数guass查询如下
- 其中把price语句的origin点设为50是有原因的,由于价格的特性一定是越低越好,所以0~100元的所有价格的酒店都应该认为是比较好的,而100元以上的酒店就慢慢衰减
- 如果我们将price的origin点设置成100,那麽价格低于100元的酒店的评分反而会变低,这不是我们期望的结果,与其这样不如将origin和offset同时设成50,只让price大于100元时评分才会变低
- 虽然这样设置也会使得price小于0元的酒店评分降低没错,不过现实生活中价格不会有负数,因此就算price<0的评分会下降,也不会对我们的搜索结果造成影响(酒店的价格一定都是正的)
- 换句话说,其实只要把
origin + offset的值设为100,origin或offset是什麽样的值都无所谓,只要能确保酒店价格在100元以上的酒店会衰减就好了GET 127.0.0.1/mytest/doc/_search { "query": { "function_score": { "query": { "match_all": {} }, "functions": [ // 第一个gauss加强函数,决定距离的衰减率 { "gauss": { "location": { // origin点设成市中心的经纬度座标 "origin": { "lat": 51.5, "lon": 0.12 }, // 距离中心点2km以内都是满分1.0,2km外开始衰减 "offset": "2km", // 衰减率 "scale": "3km" } } }, // 第二个gauss加强函数,决定价格的衰减率,因为用户对价格更敏感,所以给了这个gauss加强函数2倍的权重 { "gauss": { "price": { "origin": "50", "offset": "50", "scale": "20" } }, "weight": 2 } ] } } }