ElasticSearch Issues
1.注意事项
1.1 Segment二三事
- segment是全部的倒排表
- segment占用的内存无法被JVM GC
- 控制巨大的Mapping,尤其是nested object
- segment占用与索引(分片)数量关系不太大
- 核心指标是数据量
- force merge
- 可以降低15%-20%的内存占用
- 降低IO,提高查询效率
- /_cat/segments/{index}
- 磁盘至少有2倍以上的剩余空间
- 仔细看监控
1.2 集群状态同步
- 避免大规模的meta操作
- 集中创建大量索引
- 非常容易出现无响应/2.x直接死锁
- 推荐使用2.x+
- 增量同步state diff
- 1.x应分批分时段做meta操作
1.3 Mapping错误
- 最常见的问题
- 影响
- 修复手段
- 优先修复输入数据
- 设置replica=0(强烈不推荐)
1.4 只索引查询条件
- 不是所有的东西都需要建立索引
- 数据库也是一样!
- index: no
- 不影响查询/聚合结果
- 收益
- 倒排索引(Segment)=> [0.4%, 67%]
- 磁盘空间 => [9.8%, 24%]
- 成本下降
1.5 写入优化
- 统一设置,防止部分节点429
- threadpool.bulk.size
- threadpool.bulk.queue_size
- processors(默认超过32核按照32算)
- 官方推荐单个BulkRequest 8~15 mb
- 导数
- 关闭refresh_interval
- 关闭replica/action.write_consistency=one
- 手工refresh/flush
1.6 Refresh vs Flush
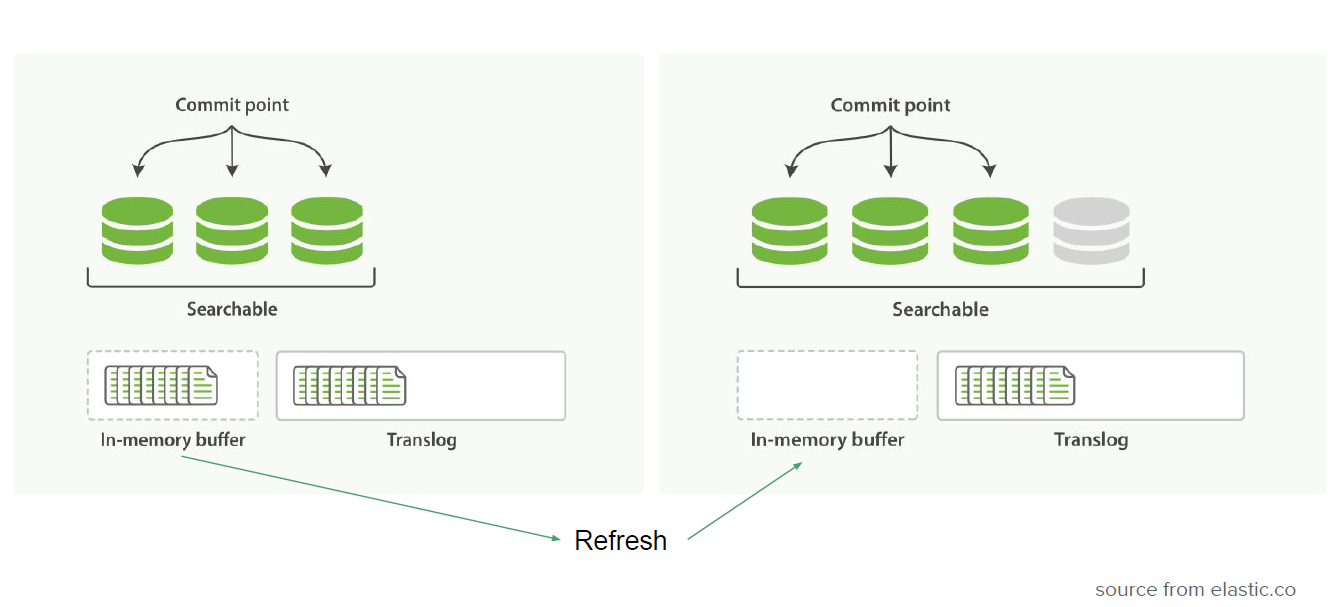
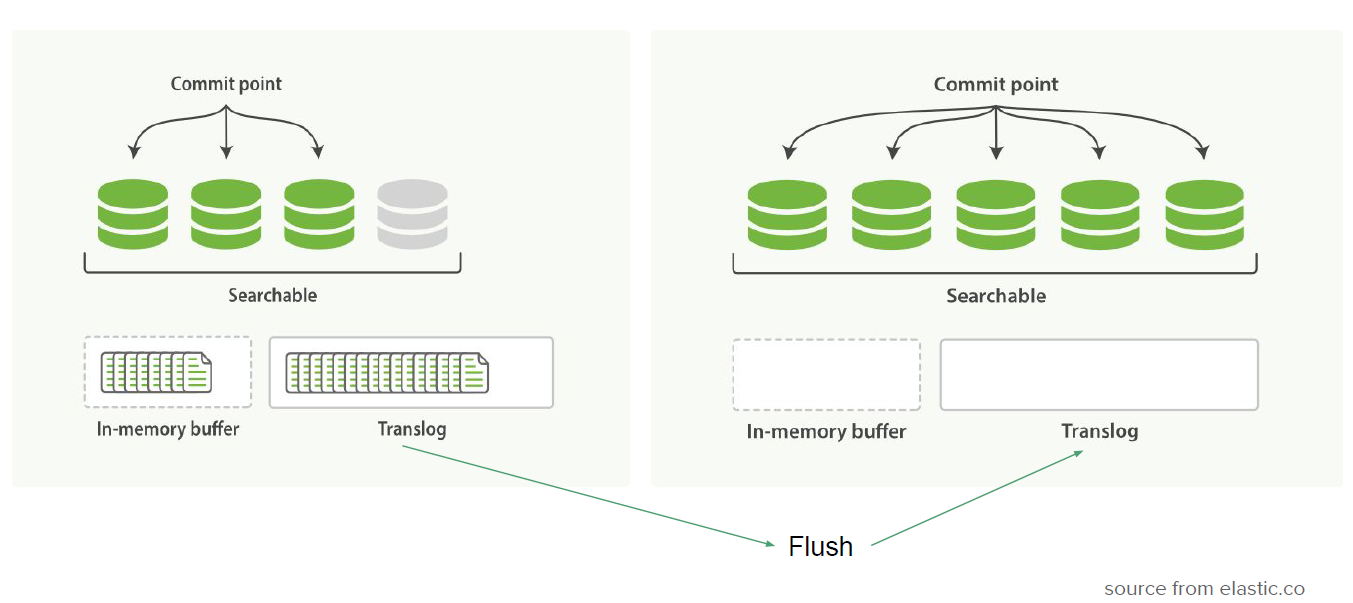
- 场景区分
- 日志集群
- refresh ~ 20s
- flush ~ 30s ~ [1x refresh, 2x refresh]
- HDD 无raid
- refresh < 1s
- flush < 5s
- SSD (磁盘容量检测60%)
- 设置translog_ops
- 减小transolog,降低故障恢复时间
- 刷新间隔太小对IO有额外开销(fsync)
- 默认配置最多丢64kb数据
注意事项
- 过小的refresh间隔将导致
- 不要对merge限流
- 目前日志集群的IO使用率平均在15~18%之间
- 峰值60%,持续时间短,多recovery/rebalance导致
- recovery的速度受translog影响
- 尽量保证人工重启前执行refresh+flush
- cluster.routing.allocation.node_concurrent_recoveries
- indices.recovery.concurrent_streams